
Il problema¶
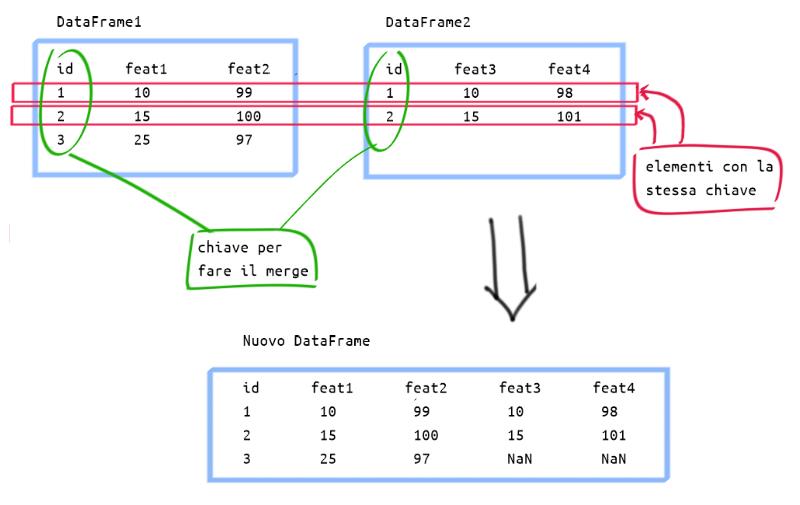
In questo articolo voglio vedere come unire 2 DataFrame di Pandas. Il problema è inquadrato nella figura sotto, dati due DataFrame che contengono dati diversi voglio combinare questi due in modo da avere un unico DataFrame alla fine del processo.
Pandas mette a disposizione la funzione merge() per fare questa unione.
L’unione verrà fatta sulla base di una chiave (id nell’esempio), gli elementi dei due DataFrame con lo stesso id vengono combinati in una unica riga nel nuovo DataFrame.
Se un id non è comune ai due DataFrame… ci sono diverse possibilità. Nell’esempio sotto ho fatto un inner merge in cui ho usato solo gli id comuni ai due DataFrame di partenza. Vedremo più avanti le altre possibilità.
Unione orizzontale¶
Generiamo 2 DataFrame
import pandas as pd
primo_df = pd.DataFrame(columns=("id_paziente", "nome", "cognome"), data=[[1, 'Pippo', 'Baudo'],
[2, 'Nino', 'Frassica'],
[3, 'Renzo', 'Arbore']])
secondo_df = pd.DataFrame(columns=("id_paziente", "altezza", "peso"), data=[[2, 173, 97],
[1, 184, 98]])
print(primo_df.head())
print('\n')
print(secondo_df.head())
Voglio unire ‘orizzontalemente’ i due DataFrame creati, per fare questo posso usare il metodo pd.merge() e indicando quale chiave usare per il merge usando il parametro on=’nome-colonna’.
Per esempio se uso come chiave id_paziente, il sistema cercherà gli elementi con lo stesso id_paziente nei due DataFrame e farà il merge orizzontale degli elementi con lo stesso id_paziente.
Usando il merge() senza nessuna specificazione del parametro ‘how’
pd.merge(left=primo_df, right=secondo_df, on='id_paziente')
Equivale al default how = ‘inner’. In questo caso verranno usate come chiavi del DataFrame risultate le chiavi comuni tra i due (o l’intersezione delle chiavi se preferite).
Come si vede il terzo elemento del primo DateFrame viene eliminato nel DataFrame risultante
pd.merge(left=primo_df, right=secondo_df, how='inner', on='id_paziente')
Usando how=’outer’ invece viene fatta una unione delle chiavi. Se un DataFrame non ha alcune delle chiavi gli elementi mancnto vengono riempiti con NaN
pd.merge(left=primo_df, right=secondo_df, how='outer', on='id_paziente')
Specificando il parametro how=’left’ il merge utilizza tutti gli elementi della chiave (keys) del DataFrame specificato col parametro left=’nome-dataframe’, la chiave è sempre specificata con il parametro on=’nome-colonna’.
Se l’altro DataFrame manca di alcuni (o tutti) gli elementi della chiave gli elementi mancanti verranno riempiti con NaN.
pd.merge(left=primo_df, right=secondo_df, how='left', on='id_paziente')
Analogamente se uso come parametro how=’right’ verranno usate le chiavi del DataFrame specificato in right=’nome-datafame’.
Come si vede poichè in questo caso il DataFrame di destra ha meno chiavi del DataFrame di sinistra, le chiavi in eccesso del DataFrame di sinistra verranno eliminate.
pd.merge(left=primo_df, right=secondo_df, how='right', on='id_paziente')
Un altro modo di usare il metodo merge() è quello di usare direttamente il metodo dello specifico DataFrame, per esempio
primo_df.merge(secondo_df, how='outer', on='id_paziente')
Un caso particolare è quando i due DataFrame hanno chiavi di nomi diversi, per esempio
primo_df = pd.DataFrame(columns=("id_paziente", "nome", "cognome"), data=[[1, 'Pippo', 'Baudo'],
[2, 'Nino', 'Frassica'],
[3, 'Renzo', 'Arbore']])
secondo_df = pd.DataFrame(columns=("dati_paziente", "altezza", "peso"), data=[[2, 173, 97],
[1, 184, 98]])
in questo caso posso indicare separatamente quale chiave usare per il DataFrame di sinistra e quale chiave per il DataFrame di destra
pd.merge(left=primo_df, right=secondo_df, left_on="id_paziente", right_on='dati_paziente', how='outer')
In questo caso dal momento che, uno dei due tra id_paziente e dati_paziente è ridondante posso decidere di eliminare una delle due colonne. Usando il metodo drop() con parametri il nome della colonna da eliminare e l’asse verticale (axis=1) per indicare si tratta di una colonna
pd.merge(left=primo_df, right=secondo_df, left_on="id_paziente", right_on='dati_paziente', how='outer').drop('dati_paziente', axis=1)
Unione verticale¶
Voglio fare il merge orizzontale ei due DataFrame contenenti lo stesso tipo di dati (aka le stesse colonne)
primo_df = pd.DataFrame(columns=("id_paziente", "nome", "cognome"), data=[[3, 'Pippo', 'Baudo'],
[1, 'Nino', 'Frassica'],
[2, 'Renzo', 'Arbore']])
secondo_df = pd.DataFrame(columns=("id_paziente", "nome", "cognome"), data=[[4, 'Gigi', 'D''alessio'],
[5, 'Massimo', 'Ranieri']])
in questo caso è sufficiente non indicare nessuna chiave e specificare che si tratta di un outer merge
pd.merge(primo_df, secondo_df, how='outer')
oppure
primo_df.merge(secondo_df, how='outer')
Conclusione¶
Ho affrontato un argomento che agli inesperti, come me, da sempre dei grattacapi: il merge di due DataFrame di Pandas.
Abbiamo visto come fare un merge orizzontale e un merge verticale. Abbiamo visto le diverse opzioni per specificare come vogliamo fare il merge.