
Nelle versioni di Apache Spark 1.x gli RDD erano lo standard per la memorizzazione distribuita dei dati. A partire dalla versione 2.x il ruolo di struttura principale di memorizzazione dei dati è stato assunto dai DataFrame. Ma la RDD API è rimasta e gli RDD sono ancora utilizzati d Spark under the hood.
Un RDD è una collezione di dati che sono partizionati (con ridondanza) tra i nodi del cluster Spark.
RDD sta per resilient distributed dataset, la chiave è il termine resilient, ovvero resistente. Un RDD è resistente alla perdita dei dati, ovvero la memorizzazione dei dati è ridondante per cui se un nodo del cluster dovesse andare giù, il RDD comunque non subirebbe una perdita dei dati. In questo articolo vediamo un esempio di come operare con gli RDD.
Il dataset
Sul sito datasets.wri.org troviamo un dataset con i dati sulle centrali elettriche mondiali. Scarichiamo il file csv.
Per leggere i dati dal file csv possiamo importare i dati in un RDD, e poi convertire il RDD in un DataFrame.
val data = sc.textFile("globalpowerplantdatabasev120/global_power_plant_database.csv")
data: org.apache.spark.rdd.RDD[String] = globalpowerplantdatabasev120/global_power_plant_database.csv MapPartitionsRDD[1] at textFile at <console>:25
Il dataset consta di 29911 righe
data.count()
res2: Long = 29911
Stampiamo i primi 5 elementi del RDD
data.take(5).foreach(println)
country,country_long,name,gppd_idnr,capacity_mw,latitude,longitude,primary_fuel,other_fuel1,other_fuel2,other_fuel3,commissioning_year,owner,source,url,geolocation_source,wepp_id,year_of_capacity_data,generation_gwh_2013,generation_gwh_2014,generation_gwh_2015,generation_gwh_2016,generation_gwh_2017,estimated_generation_gwh
AFG,Afghanistan,Kajaki Hydroelectric Power Plant Afghanistan,GEODB0040538,33.0,32.3220,65.1190,Hydro,,,,,,GEODB,http://globalenergyobservatory.org,GEODB,1009793,2017,,,,,,
AFG,Afghanistan,Mahipar Hydroelectric Power Plant Afghanistan,GEODB0040541,66.0,34.5560,69.4787,Hydro,,,,,,GEODB,http://globalenergyobservatory.org,GEODB,1009795,2017,,,,,,
AFG,Afghanistan,Naghlu Dam Hydroelectric Power Plant Afghanistan,GEODB0040534,100.0,34.6410,69.7170,Hydro,,,,,,GEODB,http://globalenergyobservatory.org,GEODB,1009797,2017,,,,,,
AFG,Afghanistan,Nangarhar (Darunta) Hydroelectric Power Plant Afghanistan,GEODB0040536,11.55,34.4847,70.3633,Hydro,,,,,,GEODB,http://globalenergyobservatory.org,GEODB,1009787,2017,,,,,,
Come si vede la prima riga contiene l’header del file csv, ovvero i nomi di ciascuna colonna del file csv.
Siccome vogliamo un RDD di soli dati numerici devo eliminare la prima colonna.
Per fare ciò uso il metodo filter(), definendo un filtro che cattura tutti gli elementi tranne la prima stringa contenuta nella prima riga.
Inizio col definire una variabile contenente la stringa della prima riga usando il metodo first()
val dataheader = data.first()
dataheader: String = country,country_long,name,gppd_idnr,capacity_mw,latitude,longitude,primary_fuel,other_fuel1,other_fuel2,other_fuel3,commissioning_year,owner,source,url,geolocation_source,wepp_id,year_of_capacity_data,generation_gwh_2013,generation_gwh_2014,generation_gwh_2015,generation_gwh_2016,generation_gwh_2017,estimated_generation_gwh
Adesso filtro tutti gli elementi che soddisfano la condizione x != dataheader, questi elementi sono inclusi nel nuovo RDD
val data_no_header = data.filter(x => (x != dataheader))
data_no_header: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at filter at <console>:29
Il primo elemento del nuovo RDD non contiene più l’header ma i dati del dataset
data_no_header.first()
res4: String = AFG,Afghanistan,Kajaki Hydroelectric Power Plant Afghanistan,GEODB0040538,33.0,32.3220,65.1190,Hydro,,,,,,GEODB,http://globalenergyobservatory.org,GEODB,1009793,2017,,,,,,
Si può vedere sotto che ciascun elemento del RDD è una lunga stringa, contenente i dati separati da una virgola.
data_no_header.take(1)
res7: Array[String] = Array(AFG,Afghanistan,Kajaki Hydroelectric Power Plant Afghanistan,GEODB0040538,33.0,32.3220,65.1190,Hydro,,,,,,GEODB,http://globalenergyobservatory.org,GEODB,1009793,2017,,,,,,)
Adesso voglio separare i dati contenuti nelle stringhe. Inizio con l’usare il metodo split() su ciascuna stringa. Il risultato è che ogni stringa è convertita in un Array di stringhe.
val data_array = data_no_header.map(x => x.split(','))
data_array.take(1)
data_array: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[9] at map at <console>:31
res8: Array[Array[String]] = Array(Array(AFG, Afghanistan, Kajaki Hydroelectric Power Plant Afghanistan, GEODB0040538, 33.0, 32.3220, 65.1190, Hydro, “”, “”, “”, “”, “”, GEODB, http://globalenergyobservatory.org, GEODB, 1009793, 2017))
Problema nr. 1
Supponiamo di volere calcolare il dato della produzione totale annuale di energia in Italia.
Per sapere cosa sono i dati nell’array posso fare riferimento al valore precedentemente definito dataheader.
Scopriamo che i dati che ci interessano sono nel primo campo (country), nell’ottavo (primary_fuel) e nel 24-esimo (estimated_generation_gwh). Si ricordi comunque che in Scala il primo elemento dell’Array ha posizione 0.
dataheader
res9: String = country,country_long,name,gppd_idnr,capacity_mw,latitude,longitude,primary_fuel,other_fuel1,other_fuel2,other_fuel3,commissioning_year,owner,source,url,geolocation_source,wepp_id,year_of_capacity_data,generation_gwh_2013,generation_gwh_2014,generation_gwh_2015,generation_gwh_2016,generation_gwh_2017,estimated_generation_gwh
Inizio con il filtrare tutte e solo le righe in cui il primo elemento dell’array contiene il codice country=‘ITA’.
val data_ita = data_array.filter(x => x(0) == "ITA") data_ita.take(2)
data_ita: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[10] at filter at <console>:33
res10: Array[Array[String]] = Array(Array(ITA, Italy, ACCEGLIO, WRI1021706, 19.0, 44.4742, 7.0183, Hydro, “”, “”, “”, “”, “”, ENTSOE, https://transparency.entsoe.eu/generation/r2/installedCapacityPerProductionUnit/show, WRI, 1015906, “”, “”, “”, “”, “”, “”, 85.53859855441274), Array(ITA, Italy, ACERRA, WRI1021322, 72.0, 40.9319, 14.3850, Other, “”, “”, “”, “”, “”, ENTSOE, https://transparency.entsoe.eu/generation/r2/installedCapacityPerProductionUnit/show, GEODB, 1053275|1067259, “”, “”, “”, “”, “”, “”, 123.74414976599063))
Si noti che il motivo per cui ho filtrato i dati sopra è quello di ridurre il dataset al minimo indispensabile, cioè ai dati relativi solo all’Italia e ai campi che ci servono. In questo modo il lavoro del cluster è semplificato e velocizzato, poiché ci sono meno dati da spostare nella rete.
Adesso posso selezionare solamente la colonna di dati che mi interessa quella con i valori della produzione energetica, colonna numero 24
val data_ita_keyvalue = data_ita.map(x => (x(0), x(23).toDouble))
data_ita_keyvalue: org.apache.spark.rdd.RDD[(String, Double)] = MapPartitionsRDD[11] at map at <console>:35
Il risultato della mappatura precedente è un RDD di coppie (chiave, valore) o (key, value). Un RDD di coppie (key, value) ha una serie di metodi dedicati, tra cui reduceByKey().
Adesso applico il metodo reduceByKey() sulle coppie (chiave, valore) del RDD. Questo metodo seleziona tutti gli elementi aventi la stessa chiave e sui corrispondenti valori applica la funzione che indico come argomento del metodo. Nel codice sotto a e b sono i valori di due diverse coppie (chiave, valore), quindi a e b sono scalari che posso sommare tra loro.
val somma_produzione = data_ita_keyvalue.reduceByKey( (a,b) => a+b ).collect()
somma_produzione: Array[(String, Double)] = Array((ITA,258640.99999999994))
Domanda
Ma quanto è la produzione di energia in Italia?
val somma = somma_produzione(0)._2 println(f"La produzione stimata di energia elettrica totale in Italia è di $somma%.2f GWh")
La produzione stimata di energia elettrica totale in Italia è di 258641.00 GWh
somma: Double = 258640.99999999994
Aggregazione dei dati
Naturalmente avrei potuto decidere di lavorare su tutto il dataset senza restringere il RDD ai dati relativi all’Italia. In questo modo posso avere il dato aggregato della produzione di energia per ogni stato del database. Vediamo come procedere.
Innanzitutto con una map() seleziono solo i dati delle colonne country e estimated_generation_gwh e al contempo converto le stringhe di x(23) in double usando il metodo toDouble(). Il risulato sarà un RDD di coppie (chiave, valore).
val data_kv = data_array.map(x => (x(0), x(23).toDouble))
data_kv: org.apache.spark.rdd.RDD[(String, Double)] = MapPartitionsRDD[56] at map at <console>:33
Vediamo la prima coppia (chiave, valore) cosa contiene
data_kv.take(1)
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 131.0 failed 1 times, most recent failure: Lost task 0.0 in stage 131.0 (TID 79, localhost, executor driver): java.lang.ArrayIndexOutOfBoundsException: 23
at $anonfun$1.apply(<console>:33)
at $anonfun$1.apply(<console>:33)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:409)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:393)
⋮
Come si vede ottengo un errore, precisamente java.lang.ArrayIndexOutOfBoundsException. Stranamente non avevo ricevuto lo stesso errore quando ho usato la stessa procedura per i dati dell’Italia.
Dopo un po di investigazioni mi accorgo che il problema sta nel fatto che l’ultimo campo ( x(23) ) alla fine di alcune righe è vuoto perché la funzione split(), che abbiamo usato per convertire la stringa singola letta dal file, non converte i campi vuoti alla fine della stringa. Ovvero:
split("AFG, 100, 12500,,,,")
viene convertito in
Array[String] = ["AFG", "100", "12500"]
Per fare in modo che la conversione contenga anche i campi vuoti devo usare un secondo parametro in split() ovvero:
split("AFG, 100, 12500,,,,", -1)
viene convertito in
Array[String] = ["AFG", "100", "12500", "", "", "", ""]
esattamente ciò di cui abbiamo bisogno per evitare l’errore ArrayIndexOutOfBoundsException.
data_no_header.map(x => x.split(",", -1)).map(x => (x(0), x(23))).collect()
res110: Array[(String, String)] = Array((AFG,””), (AFG,””), (AFG,””), (AFG,””), (AFG,””), (AFG,””), (AFG,””), (ALB,89.13207547169812), (ALB,1650.5939902166317), (ALB,1980.712788259958), (ALB,16.50593990216632), (ALB,79.22851153039832), (ALB,82.52969951083159), (ALB,825.2969951083159), (ALB,0.0), (DZA,2152.249818828645), (DZA,293.8648791092957), (DZA,2317.807497200079), (DZA,413.8941959285856), (DZA,1862.523881678635), (DZA,1862.523881678635), (DZA,1208.57105211147), (DZA,4966.730351143026), (DZA,1730.0777389814875), (DZA,298.0038210685816), (DZA,2483.365175571513), (DZA,827.7883918571712), (DZA,2036.3594439686408), (DZA,254.0), (DZA,2433.697872060083), (DZA,1427.93497595362), (DZA,4966.730351143026), (DZA,1639.0210158771988), (DZA,3476.711245800119), (DZA,761.5653205085974), (DZA,4056.1…
Ottengo un array di coppie (stringa, stringa), ma se voglio fare operazioni matematiche sul secondo elemento della coppia devo convertire quest’ultimo in un valore numerico.
Per la conversione della stringa normalmente basterebbe usare il metodo String.toDouble().
Ma a causa del fatto che ci sono stringhe vuote, il metodo toDouble() sulla stringa vuota darebbe errore.
Allora definiamo una funzione che riceve in ingresso una stringa, converte il suo contenuto in Double, usando il metodo toDouble(), e in caso la stringa sia vuota ritorna il valore 0.
def convert_to_Double(x: String): Double = {
if (x != "") {
x.toDouble
} else {
0
}
}
convert_to_Double: (x: String)Double
Verifichiamo che funzioni:
print(convert_to_Double("25"))
print("\n")
print(convert_to_Double(""))
25.0
0.0
Ovviamente lo svantaggio di questo metodo è che non so se un risultato pari a zero corrisponde ad una produzione nulla o ad una mancanza di dati.
Adesso procedo con la stessa analisi fatta in precedenza, siccome conosco i vari passaggi posso eseguirli tutti in una singola riga di codice, questi sono i singoli passaggi:
– dato un RDD composto da stringhe
– divido ogni stringa nei singoli campi con split(“,”)
– mappo ogni riga in modo da avere solo il campo country_code e estimated_production, ottenendo un RDD di coppie (key, value)
– con reduceByKey() aggrego tutte le righe aventi la stessa chiave
– collect() e println()
val data_agg = data_no_header.map(x => x.split(",", -1)).map(x => (x(0), convert_to_Double(x(23)) )).reduceByKey((a,b) => a+b)
data_agg.collect().foreach(println)
(SVN,16869.0)
(FIN,67265.99999999999)
(BLR,34041.99999999999)
(VNM,140913.00000000006)
(ROU,63069.0)
(FJI,0.0)
(GHA,0.0)
⋮
(LBN,17759.0)
(ESP,278749.9999999994)
(MDG,0.0)
(NZL,42867.99999999999)
(MYS,147468.99999999997)
(CHE,67258.00000000001)
data_agg: org.apache.spark.rdd.RDD[(String, Double)] = ShuffledRDD[63] at reduceByKey at <console>:33
Se voglio ordinare in ordine decrescente per vedere quali sono le nazioni con la più alta produzione di energia elettrica posso usare il metodo sortBy(). Come ogni altro metodo per lavorare sugli RDD questi si aspetta come parametro una funzione che restituisce un valore numerico per ogni valore del RDD.
Inoltre l’ordinamento viene fatto in direzione crescente per default, per invertire la direzione dobbiamo moltiplicare per -1.
Per indicare che voglio ordinare sul secondo elemento della coppia (chiave, valore) devo usare la notazione x._2. Contrariamente agli array, dove il primo elemento ha posizione 0, nei tuple il primo elemento ha posizione 1.
data_agg.sortBy( x => (x._2 * -1) ).take(10)
res114: Array[(String, Double)] = Array((CHN,5621543.999999972), (JPN,1011747.9999999998), (RUS,984212.0), (USA,760222.293761999), (CAN,655943.9999999995), (DEU,627697.0000000007), (BRA,590631.9999999984), (FRA,557930.0000000016), (KOR,549440.0000000001), (GBR,338923.0000000005))
Non è una sorpresa scoprire che il primo produttore di energia elettrica è la Cina, mentre il secondo è il Giappone.
Non trattandosi di un RDD di coppie (key, value) non ho a disposizione il metodo reduceByKey(), quindi dobbiamo inventarci qualcosa.
Vediamo di passare ad un problema più complicato.
Problema nr. 2
Voglio sapere quanto è la produzione di energia di ogni stato suddivisa per ogni fonte di energia.
Iniziamo con il ridurre il dataset ai soli dati che mi interessano, in questo caso sono i campi country, primary_fuel e estimated_generation_gwh. Come in precedenza il valore di potenza generata viene convertito in Double.
Le operazioni String -> Array e selezione dei campi possono essere fatte in un solo comando.
val data_reduced = data_no_header.map( x=>x.split(",",-1)).map(x => (x(0), x(7), convert_to_Double(x(23))))
data_reduced.take(5)
data_reduced: org.apache.spark.rdd.RDD[(String, String, Double)] = MapPartitionsRDD[68] at map at <console>:37
res116: Array[(String, String, Double)] = Array((AFG,Hydro,0.0), (AFG,Hydro,0.0), (AFG,Hydro,0.0), (AFG,Hydro,0.0), (AFG,Gas,0.0))
Il RDD data_reduced è costituito da tuple a 3 elementi (String, String, Double).
Adesso raggruppo usando groupBy() e indicando come chiavi il primo e il secondo elemento del tuple, cioè country e primary_fuel.
Il risultato sarà un tuple in cui il primo elemento è a sua volta un tuple (country, primary_fuel) e il secondo elemento una Sequenza di numeri indicanti la produzioni delle varie centrali corrispondenti alla combinazione (country, primary_fuel).
Come esempio di una operazione di groupby su un RDD si veda la figura sotto.
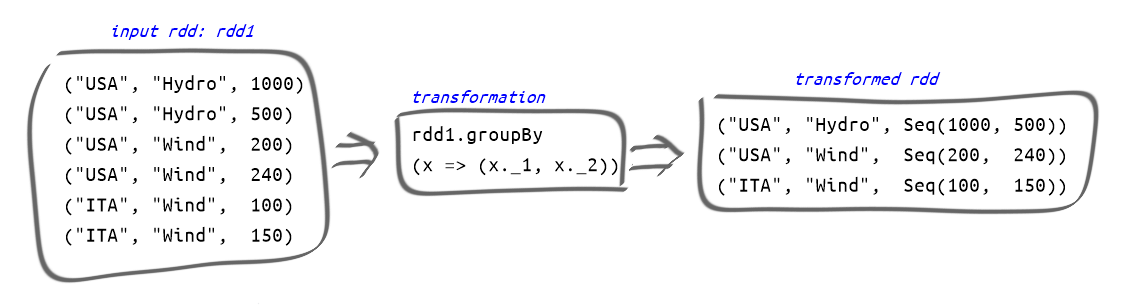
val data_grouped = data_reduced.groupBy( x => (x._1, x._2)) data_grouped.take(1)
data_grouped: org.apache.spark.rdd.RDD[((String, String), Iterable[(String, String, Double)])] = ShuffledRDD[47] at groupBy at <console>:37
res94: Array[((String, String), Iterable[(String, String, Double)])] = Array(((SVN,Nuclear),CompactBuffer((SVN,Nuclear,6370.0))))
Come si può vedere sopra gli elementi del RDD sono ((String, String), Iterable[(String, String, Double)]), più specificatamente si può scrivere ((country, primary_fuel), Iterable[(country, primary_fuel, estimated_generation_gwh)]).
Voglio ridurre questo tuple (mostruso) in (String, String, Double) ovvero (country, primary_fuel, sum(estimated_generation_gwh).
Per farlo scrivo una funzione che riceve in ingresso un tuple ((String, String), Iterable[(String, String, Double)]) e fa la somma dei valori di energia generata.
Si noti che il tipo Iterable è per definizione iterabile con un for loop, quindi mi basta iterare sugli elementi del Iterable e accumulare il valore in una variabile.
La dichiarazione della funzione è piuttosto elaborata:
def proc_group2(input: ((String, String), Iterable[(String, String, Double)])): (String, String, Double)
def proc_group(input: ((String, String), Iterable[(String, String, Double)])): (String, String, Double) = {
//definisco una variabile (var) in quanto sum deve cambiare valore
var sum = 0.0
//facciamo un loop sull'elemento Iterable del tuple
for (elem <- input._2){
// println("summing "+ elem._3)
sum += elem._3
// println("sum is " + sum)
}
//l'ultima riga della funzione è quello che la funzione ritorna
(input._1._1, input._1._2, sum)
}
proc_group: (input: ((String, String), Iterable[(String, String, Double)]))(String, String, Double)
Verifichiamo che funzioni, prendiamo un elemento a caso e lo forniamo come input della funzione:
val input = data_grouped.take(5)(4)
println("Produzione di " + input._1._1 + '\n')
val prodAggregata = proc_group(input)
println(f"La produzione di energia di ${prodAggregata._1} mediante centrali di tipo ${prodAggregata._2} è di ${prodAggregata._3}\n")
Produzione di DOM
La produzione di energia di DOM mediante centrali di tipo Oil è di 9642.0
input: ((String, String), Iterable[(String, String, Double)]) = ((DOM,Oil),CompactBuffer((DOM,Oil,2117.3465558194775), (DOM,Oil,480.95486935866984), (DOM,Oil,1146.2757719714964), (DOM,Oil,4924.061757719715), (DOM,Oil,973.3610451306414)))
prodAggregata: (String, String, Double) = (DOM,Oil,9642.0)
Per finire mappo il RDD data_grouped con la funzione proc_group
val data_aggregated = data_grouped.map(proc_group) data_aggregated.take(5).foreach(println)
(SVN,Nuclear,6370.0)
(GBR,Wind,32015.000000000025)
(USA,Wind,4317.620910000014)
(ARM,Nuclear,2465.0)
(DOM,Oil,9642.0)
data_aggregated: org.apache.spark.rdd.RDD[(String, String, Double)] = MapPartitionsRDD[51] at map at <console>:45
Adesso se voglio posso filtrare tutti i dati relativi agli USA per esempio
data_aggregated.filter( x => x._1=="USA").collect().foreach(println)
(USA,Wind,4317.620910000014)
(USA,Petcoke,0.0)
(USA,Solar,7617.67086999997)
(USA,Storage,0.0)
(USA,Geothermal,3120.476999999997)
(USA,Waste,0.0)
(USA,Oil,28942.813017000062)
(USA,Gas,159085.28519300214)
(USA,Nuclear,0.0)
(USA,Other,3226.2118600000013)
(USA,Cogeneration,0.0)
(USA,Coal,484977.23213499994)
(USA,Hydro,29065.432300000262)
(USA,Biomass,39869.550477000004)
Oppure posso selezionare i dati relativi alla produzione mediante “Waste” nel mondo
data_aggregated.filter( x => x._2=="Waste").collect().foreach(println)
(HND,Waste,0.0)
(GTM,Waste,0.0)
(RWA,Waste,0.0)
(USA,Waste,0.0)
(DEU,Waste,13503.0)
(BEL,Waste,2083.0)
(ESP,Waste,1371.9999999999998)
(AUS,Waste,0.0)
(JPN,Waste,6595.0)
(KHM,Waste,0.0)
(KOR,Waste,696.0)
(GRC,Waste,100.0)
(SGP,Waste,1260.0)
(NIC,Waste,0.0)
(PRT,Waste,489.00000000000006)
(GBR,Waste,4038.0000000000014)
(BRA,Waste,0.0)
(ZAF,Waste,0.0)
E scopriamo che lo stato dove si produce maggiormente energia bruciando l’immondizia è l’industrializzatissima Germania!
Possiamo concludere con la morale che proprio a questo serve fare questo tipo di analisi: a leggere fatti che sono nascosti tra i dati.
