
Poiché non sono riuscito a trovare informazioni chiare e definitive su come vengono gestite le partizioni in Apache Spark, ho deciso di investigare un po’ per conto mio.
Cosa ho trovato ?
Cercando su Internet ho trovato diverse informazioni che non so bene come collegare tra loro. Vediamo queste informazioni.
Nel memorizzare i dati in partizioni vengono seguite queste regole:
- Il numero di partizioni che vengono generate dipende dal numero di cores
- Ogni nodo (executor) del cluster di Spark contiene una o più partizioni
- Di default il numero di partizioni dovrebbe essere settato pari al numero di cores disponibili nel cluster, purtroppo non si può fissare direttamente il numero di partizioni
- Ogni partizione è interamente contenuta in un unico worker (o executor???)
- Spark assegna un task per ogni partizione e di default ogni core può processare un task per volta
Esempio di partitioning
Un esempio per capire l’importanza del numero di partizioni.
Supponiamo di avere un cluster con 4 core, e che i dati vengano suddivisi in 5 partizioni….
Il numero di partizioni suggerito è pari al numero di cores del cluster. In questo modo ogni nodo (supponendo 1 nodo = 1 core) riceve una partizione, e ho un numero di task pari al numero delle partizioni (core). L’utilizzo del cluster è al 100%, ovvero o tutti i nodi sono impegnati a processare la relativa partizione 👌.
Come esempio, carico un dataset di 7.55MB in un dataframe e controllo subito in quante partizioni è suddiviso il dataframe.
Per vedere il numero di partizioni uso il metodo getNumPartitions() o df.rdd.pastions.size().
val df = spark.read.option("inferSchema", "true").option("header", "true").csv("notebook/myfiles/globalpowerplantdatabasev120/*.csv")
println(f"Numero di partizioni del dataframe: ${df.rdd.partitions.size}")
Numero di partizioni del dataframe: 2 df: org.apache.spark.sql.DataFrame = [country: string, country_long: string ... 22 more fields]
Perché 2 partizioni soltanto?
Perché Spark parte di default con due executors e un core per ogni executor. Per settare un numero di executors (cores) più alto si può usare –num-executors (e –executor-cores) al momento di lanciare il cluster.
Invece di –num-executors si può settare la proprietà spark.executor.instances.
Ma prima devo stoppare la SparkSession per lanciare una nuova SparkSession con settaggi diversi.
spark.stop
E questa è la nuova SparkSession con le nuove impostazioni.
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.master("local[4]").config("spark.executor.instances", 4)
.config("spark.default.parallelism", 4).getOrCreate()
val numExecs = spark.conf.get("spark.executor.instances")
println(f"Numero di executors ${numExecs}" )
Numero di executors 4 import org.apache.spark.sql.SparkSession spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@470e03d7 numExecs: String = 4
Il setting sc.defaultMinPartitions definisce il numero minimo di partizioni quando il dataframe è creato.
Questo parametro è definito internamente da Spark come il minimo tra defaultParallelism e 2, ciò significa che defaultMinPartitions non può essere più piccolo di 2.
defaultParallelism viene settato di default pari al numero di cores usato. Posso settare questo in una nuova Sparkession con il metodo master(“local[x]”).
Si noti che anche allocando un numero alto di executor, il numero minimo di partizioni create è 2.
println(f"sc.defaultParallelism: ${spark.sparkContext.defaultParallelism}")
println(f"Numero minimo di partizioni: ${spark.sparkContext.defaultMinPartitions}")
sc.defaultParallelism: 4 Numero minimo di partizioni: 2
Diversi settaggi influiscono sul valore di sc.defaultParallelism:
- se uso master(“local[x]”) per usare x cores, defaultParallelism viene settato a x
- si può definire nello SparkSession, per es.:
val spark = SparkSession.builder().appName("TestPartitionNums").master("local").config("spark.default.parallelism", 20).getOrCreate() - si può settare nel file spark-defaults.conf con il settaggio:
spark.default.parallelism=20 - in Apache Zeppelin si può anche settare nella GUI tra i parametri dell’interprete Spark, creando un nuovo parametro con
spark.default.parallelism=20
Vediamo un esempio, ma prima dobbiamo stoppare la SparkSession.
spark.stop
Settando master("local[*]") la SparkSession userà tutti e 4 i cores del mio laptop.
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.master("local[*]").getOrCreate()
val sc = spark.sparkContext
val df = spark.read.option("inferSchema", "true").option("header", "true").csv("notebook/myfiles/globalpowerplantdatabasev120/*.csv")
println(f"Numero di partizioni: ${df.rdd.getNumPartitions}")
println(f"sc.defaultParallelism: ${sc.defaultParallelism}")
println(f"Numero minimo di partizioni: ${sc.defaultMinPartitions}")
Numero di partizioni: 8 sc.defaultParallelism: 4 Numero minimo di partizioni: 2 import org.apache.spark.sql.SparkSession spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@7f59fe sc: org.apache.spark.SparkContext = org.apache.spark.SparkContext@3beb7dfc df: org.apache.spark.sql.DataFrame = [country: string, country_long: string ... 22 more fields]
Quindi 4 cores ha disposizione ma solo 2 partizioni, significa che 2 cores saranno impegnati a processare 2 partizioni, e altri 2 cores saranno non utilizzati. Uno spreco di risorse e anche di tempo, visto che il tempo di elaborazione sarà più lungo.
Vediamo come risolvere il problema.
Il parametro fondamentale per capire quante partizioni vengono generate è
spark.sql.files.maxPartitionBytes
Come si evince dal nome, questo parametro definisce il massimo spazio su disco per ogni partizione.
Setto questo parametro a 1M (il default è 128MB), con un file dati da 7.55MB, implica che vengono create ceil(7.55M/1M) = 8 partizioni.
Si noti che così viene rispettata la condizione defaultMinPartitions = 2.
spark.conf.set("spark.sql.files.maxPartitionBytes", "1000000")
val df = spark.read.option("inferSchema", "true").option("header", "true").csv("notebook/myfiles/globalpowerplantdatabasev120/*.csv")
println(f"sc.defaultParallelism: ${sc.defaultParallelism}")
println(f"Numero minimo di partizioni: ${sc.defaultMinPartitions}")
println(f"Numero di partizioni: ${df.rdd.getNumPartitions}")
sc.defaultParallelism: 4 Numero minimo di partizioni: 2 Numero di partizioni: 8 df: org.apache.spark.sql.DataFrame = [country: string, country_long: string ... 22 more fields]
Come volevasi dimostrare ho 8 partizioni.
Dunque, per uno sfruttamento ottimale del cluster (con 4 cores) dovremmo settare spark.sql.files.maxPartitionBytes in modo tale da avere un numero di partizioni pari a 4 (o multipli di 4). Ad esempio, se il file è di 7.55MB posso settare:
spark.sql.files.maxPartitionBytes = 2M
Caricare dati da più file
Il caso visto sopra funziona quando c’è solo un file da aprire. Di regola una grossa quantità di dati è momorizzata in più file.
Vediamo come funziona il partitioning nel caso i ati siano memorizzati in più file.
Ad esempio i miei dati sono in una cartella, i files sono nominati come segue:
- block_1.csv
- block_2.csv
… - block_10.csv
Per caricare i dati devo usare il dataFrame reader indicando semplicemente la cartella dove si trovano i dati.
In questo caso i dati sono 10 files da 25MB ciascuno, vediamo cosa succede e in quante partizioni vengono spalmati i dati. Usiamo l’impostazione di default maxPartitionBytes = 128MB.
spark.conf.set("spark.sql.files.maxPartitionBytes", 128*1024*1024)
val df = spark.read.option("inferSchema", "true").option("header", "true").csv("notebook/myfiles/blocks")
println(f"sc.defaultParallelism: ${sc.defaultParallelism}")
println(f"Numero minimo di partizioni: ${sc.defaultMinPartitions}")
println(f"Dimensione massima della partizione (in Bytes): ${spark.conf.get("spark.sql.files.maxPartitionBytes")}")
println(f"Numero di partizioni: ${df.rdd.getNumPartitions}")
sc.defaultParallelism: 4 Numero minimo di partizioni: 2 Dimensione massima della partizione (in Bytes): 134217728 Numero di partizioni: 5 df: org.apache.spark.sql.DataFrame = [id_1: int, id_2: int ... 10 more fields]
Ottengo che i 250MB sono suddivisi in 5 partizioni. Non è una suddivisione ottimale avendo 4 cores. Vuol dire che mentre i primi 4 tasks saranno finiti quasi contemporaneamente, poi rimarrà il quinto task da eseguire, quindi un solo core impegnato a lavorare e altri 3 in idle!
Perché ho questa suddivisione? Perché Spark calcola una dimensione massima della partizione usando il codice sotto:
val defaultMaxSplitBytes = sc.getConf.get(config.FILES_MAX_PARTITION_BYTES)
val openCostInBytes = sc.getConf.get(config.FILES_OPEN_COST_IN_BYTES)
val defaultParallelism = Math.max(sc.defaultParallelism, minPartitions)
val files = listStatus(context).asScala
val totalBytes = files.filterNot(_.isDirectory).map(_.getLen + openCostInBytes).sum
val bytesPerCore = totalBytes / defaultParallelism
val maxSplitSize = Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
Nel nostro caso ho:
defaultMaxSplitBytes = 128M <- default
openCostInBytes = 4M <- default
defaultParallelism = 4
totalBytes = 10*(25M+4M) = 290M
bytesPerCore = 250M/4 = 72.5M
maxSplitSize = min(128M, max(4M, 72.5M)) = 72.5M
Quindi la dimensione massima della partizione non è 128M ma 72.5M.
Ma c’è ancora un dettaglio su come viene effettuata la partizione dei dati.
- Il primo file viene caricato nella prima partizione, la dimensione dell partizione è 25M, il “costo” di aprire un altro file è 4M, quindi viene calcolato che la partizione è (25+4)M:
dimensione_corrente_della_partizione=29M - Se la somma dimensione_corrente_della_partizione + dimensione_prossimo_file è maggiore del maxSplitSize, allora il prossimo file verrà caricato in una nuova partizione. Altimenti il file fiene caricato nella partizione corrente. Iterando questa logica vengono caricati tutti i file
- Si noti che per ogni file caricato nella partizione viene aggiunto un openCostInBytes
Alla fine le partizioni sono occupate come sotto:
| Partizione 1 => | file1= 25MB | openCostInBytes = 4M | file2= 25MB | openCostInBytes = 4M |
| Partizione 2 => | file3= 25MB | openCostInBytes = 4M | file4= 25MB | openCostInBytes = 4M |
| Partizione 3 => | file5= 25MB | openCostInBytes = 4M | file6= 25MB | openCostInBytes = 4M |
| Partizione 4 => | file7= 25MB | openCostInBytes = 4M | file8= 25MB | openCostInBytes = 4M |
| Partizione 5 => | file9= 25MB | openCostInBytes = 4M | file10= 25MB | openCostInBytes = 4M |

Shuffle dei dati
Abbiamo visto come fissare il numero delle partizioni quando una struttura di dati in ingresso viene generata.
Ma il numero delle partizioni non è fisso dall’inizio alla fine della applicazione, infatti esso cambia se triggeriamo uno shuffle dei dati, ovvero se utilizziamo una trasformazione che implica uno shuffle (wide transformation).
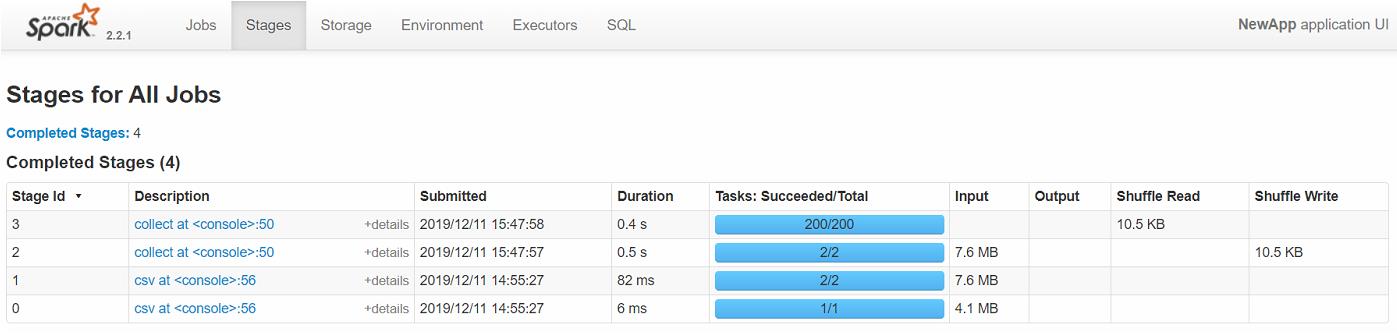
Come si può vedere sotto il numero delle partizioni dopo le operazioni groupBy() e max() è diventato 200. Perchè?
val newdf = df.groupBy("country").max("estimated_generation_gwh")
newdf.rdd.getNumPartitions
newdf: org.apache.spark.sql.DataFrame = [country: string, max(estimated_generation_gwh): double] res31: Int = 200
Come si vede sopra dopo le operazioni groupBy() e aggregate ho 200 partizioni, questo perchè il parametro spark.sql.shuffle.partitions è settato a 200. Ricordiamo che quest’ultimo fissa il numero di partizioni create da un’operazione che1 implica uno shuffle, come ad esempio groupBy.
Nella UI di Spark si può vedere come è cambiato il numero di task e conseguentemente di partizioni, da 1 a 200.
I parametri interessanti sono riassunti nella tabella
| settaggio | default | spiegazione |
|---|---|---|
| spark.driver.cores | 1 | setta il numero di cores usati dal driver |
| spark.executor.cores | 1 in modo YARN. Tutti i cores disponibili in modo Spark standalone e con Mesos | il numero di cores per ogni executor in fase di lancio del nodo |
| spark.task.cpu | 1 | numero di task da allocare per ciascun core |
| spark.cores.max | non settato | il massimo numero di cores del cluster (totale, non per ogni executor) da assegnare all’applicazione. Solo per Spark standalone e Mesos “coarse-grained” |
| spark.deploy.defaultCores | illimitato | numero default di cores del cluster da assegnare in Spark standalone se non è assegnato spark.cores.max. Si può usare per limitare il numero di cores da assegnare a diversi user di un cluster condiviso |
| spark.default.parallelism sc.defaultParallelism |
numero di cores | numero di default delle partizioni generate da operazioni quali join e reduceByKey e parallelize |
| spark.sql.files.maxPartitionBytes | 128M | dimensione massima della singola partizione |
Esempio
Supponendo di essere in cluster mode, settando:
- spark.cores.max = 5
- spark.driver.cores = 1
- spark.executor.cores = 2
avrò un numero di executors pari a
executors = (spark.cores.max - spark.driver.cores)/spark.executor.cores = 2
Infine, per controllare i settaggi del cluster Spark:
spark.conf.getAll.foreach(println)
(spark.driver.host,c1801f224934) (spark.driver.port,45177) (spark.app.name,c9595f99−da7b−4d42−a424−1f3fb172f850) (spark.driver.memory,1g) (spark.executor.instances,2) (spark.executor.id,driver) (spark.driver.cores,1) (spark.webui.yarn.useProxy,false) (spark.master,local[*]) (spark.executor.memory,1g) (spark.executor.cores,1) (spark.app.id,local−1622999305790)